Linux内存管理
限定:主要是指32位上,单节点,开启MMU,有HIGHMEM区域中的内存管理
- 物理内存管理的目标有两个:进程资源隔离,效率和性能; 通过虚拟地址和物理地址的转化,虚拟地址向进程提供统一的地址分布,而页表的转换保证了每个进程操作的物理地址不同。 对物理地址进行逻辑上分页创建了一种相同粒度上的映射单位,然后可以以一种全关联的方式进行映射管理,即一个虚拟地址理论上可以映射到任何的物理地址,实际上为了效率内核所占的部分内存是不能映射的. 效率方面,我们先看物理结构: 物理架构上来看,内存一般是接在被桥上,和显卡类似一样是离CPU最近的设备;然后有类似于南桥的东西,硬盘,USB,UART等都是连接在南桥上然后再和内存连接的。更细一点,CPU内部一般都有3级缓存,L1中数据和指令分开的,L2两者公用,L3是核间公用充当所有CPU和内存的缓冲。然后还有一个重要的设备DMA控制器,能够不占用cpu的情况下复制数据,这个真的是减少了CPU I/O等待时间。 所以效率分为两方面,利用cache来缓冲CPU和内存的速度,技术有per_cpu_pages,slab,就是减少cache miss率,性能的表现就是cache miss率; 页缓存和块缓存来缓存硬盘上的东西,减少磁盘I/O带来的延迟。 另外我们需要有DMA zone来专门进行设备I/O.
另外一方面是节约内存: 1.只有真正操作物理内存的时候再分配,这样就产生了缺页中断这种分配物理地址的手段 2.swap,swap,swap,讨厌的事情说3遍,将不经常使用的页交换到慢速设备上来腾出可用物理内存 呵呵,上面两种,一种在内存富裕的时候利用内存缓存来提升性能,另外一方面又尽量减少内存分配来节约内存(还有就是效率,例如exec),实现完美的平衡
- 其他问题: 我们知道的内存碎片问题,常常分配不出来物理连续的内存空间,围绕这个问题,有buddy系统的阶的概念,有MOVEABLE概念,有针对slab的内存压缩,针对普通内存的内存规整,CMA,KSM等技术
几种分配方式:buddy系统,per_cpu_pages,slab
在分页的基础上,我们有了buddy系统,管理以页为单位的内存,是最直接的内存管理,其他的per_cpu_pages,slab,malloc等最后都要buddy系统中直接或者间接地获得物理页.物理内存还希望是在物理上连续的,所以维护了不同阶的链表。 每当我们释放某个页之后,只是标识它是空闲的,但是它的数据却还在cache中,这样再次使用这个页时,可以直接操作cache中的数据,省却了从物理内存中load到cache的过程,因此诞生了per_cpu_pages管理. 应用程序分配的内存通常很小,远小于4k,分配的粒度太大了,这样就造成了很多页内浪费。发明了slab系列,是一种内存到内存的缓冲。
内存初始化
系统如何直到物理内存的信息?如何管理这些内存的?
在x86上我们知道是通过e820寄存器获得系统物理内存信息,不是很了解x86,暂且不表.
在ARM上有两种方式获得物理内存的信息,通过uboot传过来、通过device tree信息获得,分别在setup_machine_tags和setup_machine_fdt解析获得;目前android上大部分都是通过第二种方式传递给kernel,有一些使用uboot的仍然采用atags的方式传送过来。具体可以参考Documentation/arm/Booting
获得信息之后如何管理这些内存?
不管是x86还是arm,都会将信息保存在一种通用的结构中:memblock
struct memblock {
phys_addr_t current_limit;
struct memblock_type memory; //所有可用的内存
struct memblock_type reserved; //被系统占用的内存,将不会传递给zone管理
};
通过device tree传递的物理内存信息转换:
在setup_machine_fdt中通过early_init_dt_scan_memory来获取memory的节点,最后加入到memblock中,里面分成两部分,总的内存memblock->memory和已经被占用的内存memblock->reserved;
drivers/of/fdt.c
early_init_dt_scan_memory(unsigned long node, const char *uname,
int depth, void *data)
{
char *type = of_get_flat_dt_prop(node, "device_type", NULL);
reg = of_get_flat_dt_prop(node, "linux,usable-memory", &l);
endp = reg + (l / sizeof(__be32));
while ((endp - reg) >= (dt_root_addr_cells + dt_root_size_cells)) {
u64 base, size;
base = dt_mem_next_cell(dt_root_addr_cells, ®);
size = dt_mem_next_cell(dt_root_size_cells, ®);
early_init_dt_add_memory_arch(base, size);
}
}
上面是加入到memblock->memory中,表示总的可用物理内存;
下面就是需要将内核占用的物理内存在reserved中标示出来,通常都有的内核的text,data, initrd,swapper_pg_dir,dtb,DMA
然后在物理页面之后就是页表的初始化,在prepare_page_table清除VMALLOC之下的所有页表,重头戏都在map_lowmem->create_mapping,遍历pgd,pmd,然后分配pte空间,然后填充pte,pmd.在现在的arm中只有二级页表,pgd=pmd,关于pmd的操作就是操作pgd。
这里有个点:arm的MMU中PGD是20位,剩余的是标志位,但是在linux需要一些额外的标志位,YOUNG(表示页最近访问过),DIRTY(页内容被改变了),而arm的硬件没有这些标志位,所以需要在软件上实现这些标志,在相应的操作中,置软件标志位.实际上pgd entry仍然是4字节的,每个entry可以指向2^8个pte项,每个pte项占据4字节,所以pgd指向的pte连续空间为1024字节空间,每个页4k空间,4个pgd可以指向同一页的pte,但是这里取巧操作,每两个pgd指向一个页,公2048字节,两外的2048字节保存软件标志位;而pgd在软件上看是每个entry占据8字节,指向一页空间的pte,相邻的两个地址可以共用一个页基地址;
下面映射dma,remap,fixmap,vmalloc区域。
下面就是填充pglist_data和各个zone的数据
页表
在启动MMU的系统中如何通过虚拟地址找到物理页?MMU中的作用?
1.MMU中看到的物理地址,所以pgd,pte中存储的都是页物理地址
2.linux理论上支持4极页表,而32位上一般使用2级页表,64位上使用3级页表
3.内核的页表在swapper_pg_dir
4.mm_struct->pgd是虚拟地址,因为处于线性映射,在装入MMU之前会转换为物理地址访问
arm页表
物理页分配和释放
buddy
alloc_page
分配时提供的参数:order和gfp_t,order是指阶数,需要分配2^order;gfp_t(Get free page)中有两种标志:从那个zone中分配,称为Zone modifiers,另外一种描述是Action modifiers;可以参考include/linux/gfp.h
理想情况下页的分配:
1.通过gfp_t中找到优先从哪个zone中分配,顺带确定后备分配区域zonelist
pglist_data中有一个zonelist node_zonelists,在初始化时确定这个数组里的顺序,从低到高分别是:Highmem->normal->dma,如果确定优先从normal区域中分配,当normal中不足时尝试从dma中获取,却不会去highmem中查找。
2.查找normal中的buddy中的free_area中链表,从order阶开始查找是否有足够的页满足要求
3.如果free_area[order]上没有的话,就继续查找free_area[order]到free_area[MAX_ORDER],找到之后需要拆分高阶连续的页并且挨个放入低阶链表中(expand)
4.如果没有足够的页,尝试到后备分配区域中查找,需要满足条件:例如优先从normal中分配,现在需要到dma中分配,需要dma区域中free page > watermark[high]+lowmem_reserve[1],lowmem_reserve的计算参考说明Documentation/sysctl/vm.txt中关于lowmem_reserve_ratio和setup_per_zone_lowmem_reserve实现方式
5.如果都不满足的话,尝试进行页面回收之后再次尝试分配
引起睡眠的分配API:
slab
1.目的:slab是为小块内存分配提供的一种管理方式
2.主要管理数据
3.实现方式:
4.创建、销毁
5.分配、释放
slab:
slab可以看作是一组页,通常是一个页,当页从buddy中移到slab中管理时,slab就代表这个页
struct slab {
struct {
struct list_head list; //挂入partial,free,full中
unsigned long colouroff; //color是指缓存行,colouroff是color offset,指缓存行可以占据的空间
void *s_mem; //这个代表coloroff之后的位置
unsigned int inuse; //这个slab中有多少个对象在被使用
kmem_bufctl_t free; //这个其实是char free[kmem_cache->num],每个字节和一个obj关联
unsigned short nodeid;
};
};
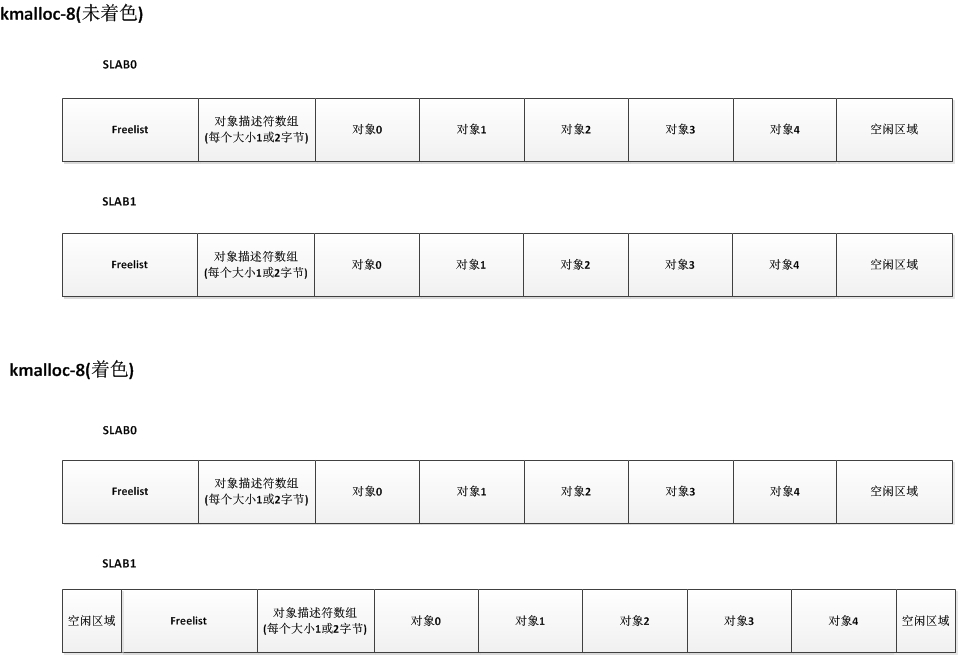
slab分配总体样子:
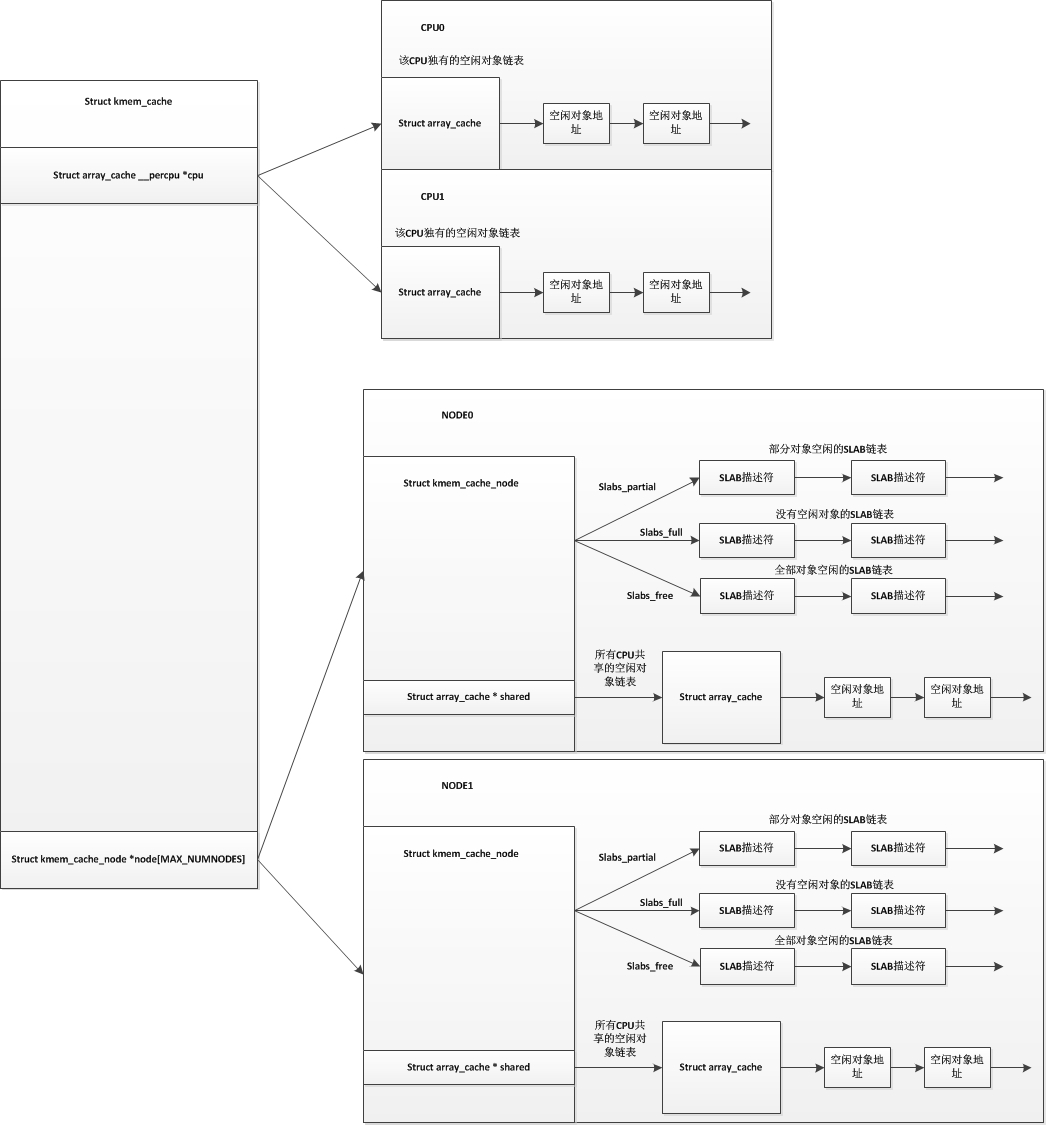
分配时,先从kmem_cache->array_cache中寻找,如果找不到再从kmem_cache->kmem_cache_node->shared中分配,然后再从kmem_cache->kmem_cache_node->slabs_free分配,不足的时候再从per_cpu_pages或buddy中分配.
per_cpu_pages
适合单个页的分配
虚拟地址空间
寻找vma
插入vma
逆向映射
anon_vma,anon_vma_chain
页缓存
其中有两个方式:页缓存和块缓存,从发展历史上来看,因为更加贴近块设备的特性,最开始使用块缓存; 然后随着各种设备:硬盘存储,文件系统等发展,存储量大幅上升(但是仍然没有解决IO慢的问题),使用块来管理就有点低效,即管理数据太多了,代价太高了. 页缓存的存在意义:读取规模比较大的操作时,使用页缓存更加方便, 块缓存:在页需要回写的时候可以通过更小粒度的块而不是整页为单位回写,一般是文件系统的元数据,量特别小 而真正和硬盘IO打交道的时候都是通过发送bio请求,所以真正影响IO速度的在这里,不过除了物理因素,IO的性能还和IO是否是顺序,读/写有关系; 其本身就是为了效率而设计的,类似于cache的作用,所以需要设计几个点: 1.读写操作时首先会查询是否在缓存中,否则发生IO miss,需要从磁盘中加载,所以查询的操作需要高效,设计出了基数树; 缓存虽然好,但是总会存在负面作用:可能在缓存中的数据已经被修改了,但是没有被回写到磁盘上就被关机,所以设计出了回写机制:定时回写,直接回写,还有用户主动通过sync来回写。 抽象模型:address_mapping 这里为了可以管理按页处理和缓存的各种不同对象,内核使用了address_mapping抽象,将内存中的页和特定的块设备关联起来。 每个地址空间都有一个宿主作为其数据来源,大多数情况下是标示一个文件的inode,少数情况下是设备本身,就是我们平时说的读文件、读设备。 address_mapping作为内存中的缓存页和inode之间的抽象层,存在一种这样的关系:每个文件系统挂载时都会生成super_block实例,关联着所有该文件系统中打开的所有文件对象inode,然 后address_mapping,然后就能遍历所有的缓存页的状态,这也是drop_caches的背后关系之一. 块缓存是如何组织的呢?
页缓存的实现?
在读的过程中,首先去address_mapping中找对应的偏移地址是否有页存在,如果没有的话则分配页,加入到address_mapping中并且真正去读数据。kuaihuanchongle
当用户空间打开文件时:用户程序最终获取到fd,而在其背后的关系:task_struct->files->file->inode->address_space
当用户空间读文件数据时,通过VFS->具体的FS->readpages->mpage_readpages,读取硬盘中的内容,
需要知道源地址和目的地址,即分配页并且知道从哪里读取,分配物理页时内存的功能,而找到目的地址这就纯粹是文件系统的设计问题了,
顺带将这些page都插入了address_mapping的基数树中,并且加入到页缓存链表中。
物理页和文件的映射关系:find_get_page(文件内的偏移/页size)
块缓存的实现:
利用了page的数据,private指向第一个buffer_head,buffer_head通过链表组成了一个环,这样就可以根据page遍历所有的buffer_head情况,查询是否需要更新,回写等.
buffer_head中保存了内存中数据的位置:b_data;指向在后备存储器上的位置:b_bdev,b_blocknr,b_size.
页缓存和块缓存的交集:
当从块设备中读取整页时,block_read_full_page调用将会首先建立块缓存和页缓存的关联,通过更细粒度的判断来减少无意义的读写动作,如果需要读取整页的话就不再需要块缓冲了,直接调用mpage_readpage,避免无意义的缓冲区操作。
然后转换为bio操作提交给IO系统,在bio操作完成之后会触发调用bh_end_io_t
从内存中向块设备中写页时,大部分时候不是整页都需要写,可能只需要写一块,那么就轮到快缓冲了。
分配页缓存:分配页,然后插入页缓存中:add_to_page_cache
查找页缓存:find_get_page
删除页缓存:从页缓存中删除释放回per_cpu_pageset/buddy中
页缓存的读写:分成两部分,分配页缓存并加入到对应的节点,然后创建bio请求等待读写完成
页缓存预读:假设页是顺序读写的,所以当发现符合顺序的规律时,就做出更加大胆的判断,预读更多的页;否则重新开始预测。
预读是在这3个地方控制的:
(1)do_generic_mapping_read,通用的读取例程
(2)缺页异常处理程序filemap_fault,负责为内存映射读取缺页
(3)__generic_file_splice_read,支持splice系统调用(一般不用鸟它)
if(absent(page)) {
alloc_pages(8)
read_pages(8)
}
页回收
两个目标:1.周期性回写数据以保持和后被存储设备上数据一致 2.当系统缓存中脏页过多时,显示刷出
什么时候变脏?怎么管理脏的inode?数据同步的处理?
当向缓存页写新的数据时,page和inode就变为脏,过程:super_block->s_bdi->wb->b_dirty上
周期性回写:
回写周期:
这个可以通过/proc/sys/vm/dirty_writeback_centisecs来控制,单位为百分之一秒
初始化过程:当初始化super_block的时候会初始化bdi(backing device info),初始化一个work_struct并且形成一个超时机制,触发之后开始处理脏数据bdi_writeback_workfn,在结束的时候重新设置定时器,形成定时刷新。
控制参数:一个是脏数据足够多,另外一个是时间间隔比较久,两个只要满足一个条件就会被flusher刷出;
dirty_background_bytes
周期性刷新时,>=dirty_background_bytes时才会开始,和dirty_background_ratio只能有一个生效
dirty_background_ratio
周期刷新时,脏页>所有可用内存xdirty_background_ratio才会开始
dirty_bytes
进程产生这么多字节脏页时会开始回写,最小为2个页面大小
dirty_expire_centisecs
当数据变脏时间大于dirty_expire_centisecs时将会被刷回
dirty_ratio
一个进程产生>(dirty_ratio x 所有可用内存)时开始自己回写数据
dirty_writeback_centisecs
周期性回写间隔,单位为百分之一秒
原来的pdflush,还有后来的bdi-default,flush-x:y等都被workqueue方式替代了,每个块设备都有一个writeback的workqueue,开启定时刷新的功能。
从内核3.6开始关于super_block的sync_supers和write_super被删掉了,原因是它的实现中包含一个定时器,无论super_block是否需要回写,总会定时唤醒,耗电,被kill掉了;
commit:vfs: kill write_super and sync_supers
回写过程:
显示刷出: 触发显示刷出的过程? sync系统调用,umount,分配页面时空闲页面不足
显示刷出和周期性回写的区别?
直接刷出,写到swap中,简单释放就是页面回收的三种方式,周期性扫描,直接页面回收,主动sync,/proc/sys/vm/drop_caches,脏页比例过高是页面回收的触发方式
周期性刷新:
控制参数:/proc/sys/vm/dirty_writeback_centisecs,单位为百分之一秒
初始化过程:当初始化super_block的时候会初始化bdi(backing device info),初始化一个work_struct并且形成一个超时机制,触发之后开始处理脏数据bdi_writeback_workfn,在结束的时候重新设置定时器,形成定时刷新。
sync:
强制所有的脏数据回写,保持和硬盘数据一致
wakeup_flusher_threads(0, WB_REASON_SYNC);
iterate_supers(sync_inodes_one_sb, NULL);
iterate_supers(sync_fs_one_sb, &nowait);
iterate_supers(sync_fs_one_sb, &wait);
iterate_bdevs(fdatawrite_one_bdev, NULL);
iterate_bdevs(fdatawait_one_bdev, NULL);
sync_inodes_one_sb只是将工作挂在bdi->work_list上,然后