进程管理
进程管理作为系统最重要的子系统之一,主要承担了虚拟化cpu的功能,在宏观上并行运行任务,而在微观上串行运行任务,就有一个问题,哪个任务运行在cpu上,运行多长时间? 另外一个任务运行不仅需要cpu,还需要内存,文件系统,信号等资源,同时为了更加充分地利用cpu,任务是有不同的状态的,当任务在等待IO的时候就不需要再使用cpu,需要让出来给其他任务使用. 所以进程管理最少关注三个方面:进程状态,进程资源管理,任务调度
进程管理主要的工作就是管理多个进程如何瓜分CPU时间,而进程有两个很重要的特征:优先级和状态
不同的进程要求不同,所有进程完全一视同仁就是最大的不公平,所以抽象出了优先级的概念,它决定了获得CPU运行时间和响应延迟
进程也是需要依赖其他资源的,它如何走过自己的一生内核也划分了不同的状态。当然,里面最重要的几种状态反应它的
能力:RUNNING,INTERRUPTIBLE,UNINTERRUPTIBLE
进程是什么,如何抽象管理的?
进程就是程序运行时的实体,只有运行时它才会占用很多的资源,否则只是占据一点存储空间。运行时的进程会根据自身代码不同占用不同的资源,完成不同的任务,但是有一些核心的资源是进程必须的:进程管理数据task_struct、打开的文件、文件系统信息、内存信息、cpu信息。
进程之间是存在很多关系的:父子,兄弟,线程组等,这些都是有专门的链表来管理:slibing,children;其中特殊的一个是所有的进程都会挂在init_task的tasks链表头中
内存是用来保存数据的,在进程运行期间负责所有数据的保存,有代码数据,堆,栈数据等
cpu信息是代表进程参与任务调度的数据:sched_entity
进程创建,销毁
创建:主要就是根据do_fork时传入的标志复制或者新建进程管理信息.
fork():就是copy父进程的task_struct,内存管理信息,文件信息,文件系统信息,信号等
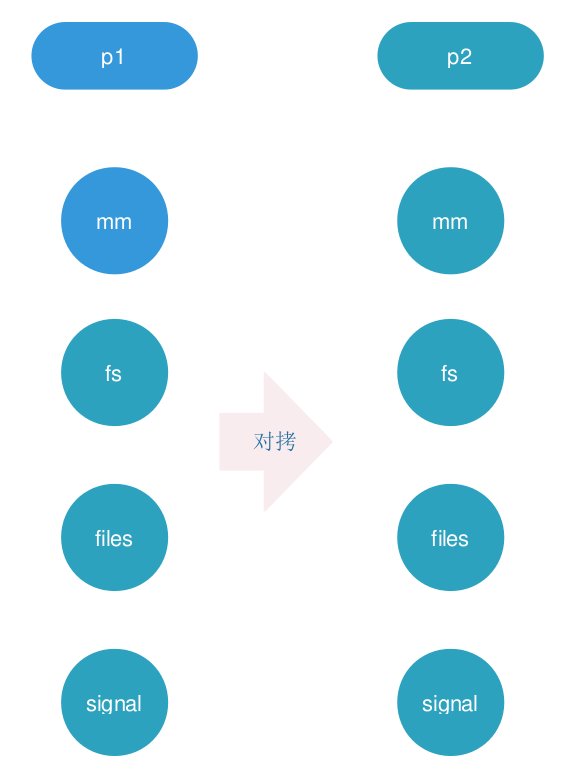
当父子进程有任何一方修改这些资源的时候都会分裂,创建独属于自己的资源
vfork():CLONE_VM,CLONE_VFORK
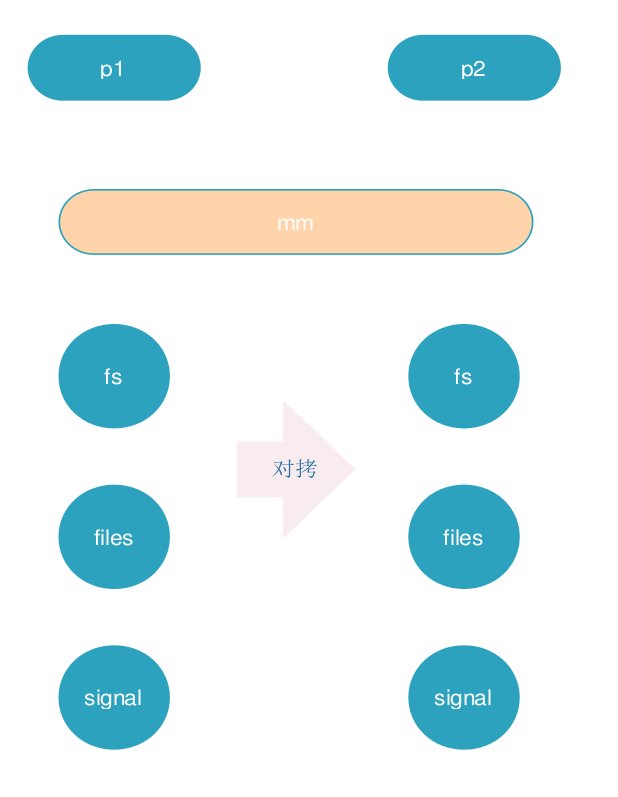
pthread_create:CLONE_VM,CLONE_FS,CLONE_FILES,CLONE_SIGHAND,CLONE_THREAD

COW:在分配资源方面系统尽可能懒惰,能延迟分配的延迟,能不分配的就不分配,能少分配的就少分配,一句话:懒也是门技术
如何瓜分CPU时间:实时调度类,普通调度类
进程如何选择调度类,实时调度类怎么瓜分进程
明白进程管理对于那些人有用?
进程生命周期
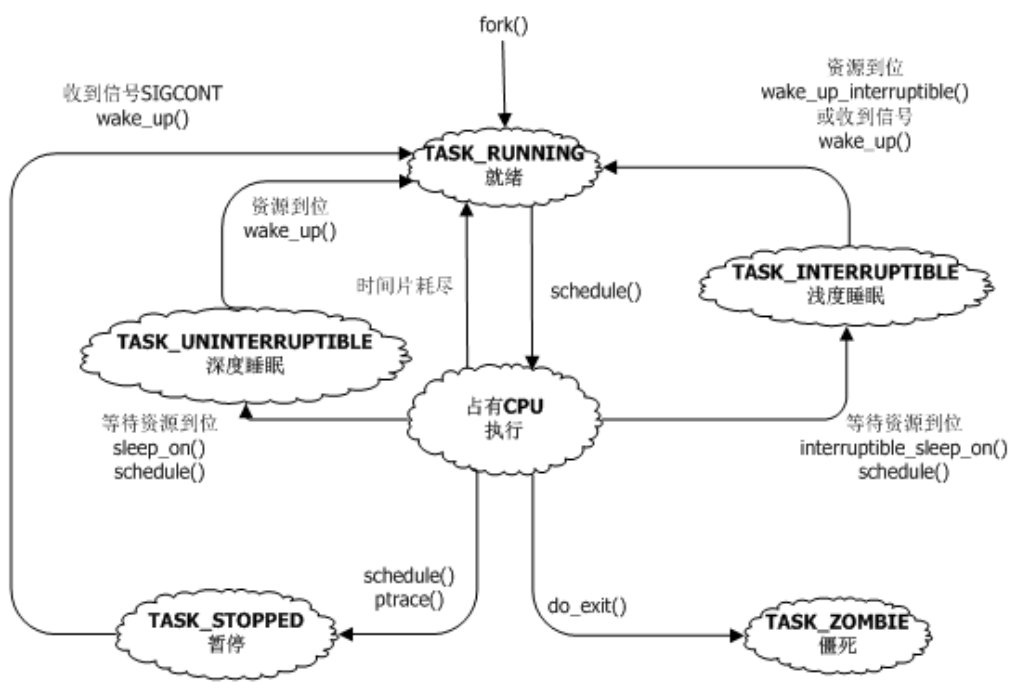
可中断睡眠和不可中断睡眠的区别:能不能被信号唤醒,都是从RUNNING状态下迁移出来,不再被调度。 一般都是设置好可以唤醒的条件,然后设置自身的状态,调用schedule(),主动让出CPU. 而不可中断的睡眠不能被信号唤醒,用户空间就完全没有办法了,只有内核能够唤醒。
僵尸进程: 当进程死去的时候,只是将所占据的资源释放掉了,但是还没有从全局进程表中移除。 父进程需要在子进程终止的时候,需要调用wait4,向内核证实父进程已经确认子进程死亡了。 父进程没有确认子进程死亡的时候,子进程就是僵尸进程了。
进程描述符
进程包含的信息分类:
1.可执行文件
2.内存mm_struct
3.cpu相关的:优先级,调度器相关的调度体,时间,统计信息等
4.打开的文件,万物皆文件,设备也是文件
5.信号,共享内存等进程间通信
6.进程的凭据:uid,gid,ppid,pid等
7.进程的状态:RUNNING,INT,UNINT,DEAD,ZOMBIE
8.进程之间的关系:全局的进程表,亲缘进程关系
9.资源限制
进程创建和销毁,唤醒
进程的创建无非就是创建管理数据,就是task_struct,并且在各种资源中完成角色建立, 使用COW的原因:进程通常只使用内存页的一部分,不经常访问父进程的全部内存页。全部复制遇到execv之后负面效应会更严重。 COW只复制页表,fork之后父子进程的地址空间指向同样的物理内存页,且对两者的页表都标记了只读属性,所以谁先写就会发生page fault.用户栈也是使用时再分配,呵呵了
孤儿进程的托孤
调度器
调度策略和调度类映射:NORMAL,BATCH,IDLE对应CFS;RR,FIFO对应于rt.
实时调度
凡是调度策略设置为实时的,调度方式是按照响应的实时策略的。在实时进程的世界里是一个阶级分明的世界
时间片分配
时间片只在rq上分配,没有RUNNING的进程是没有资格瓜分时间片的。时间片的瓜分仍然是按照进程的优先级来决定的,优先级高的获得更多的CPU运行时间。
用户空间可以使用nice命令来查看优先级,也可以通过系统调用来改变优先级,在用户空间中他理解的优先级为-20~+19,值越低,优先级越高
内核使用0-139来标示内部优先级,而0-99给实时进程使用的,100-139给普通进程使用的。
而内核中有三个优先级来表示进程真正的重要程度:
静态优先级:就是nice值看到的,用户可以修改
普通优先级:这个主要是作为非实时和实时进程优先级计算的统一接口,实时进程根据调度策略来分别的;动态提升进程的优先级时(使用了RT-Mutex),根据prio值来检测是不是临时提升到了实时进程级别.
动态优先级:这个就是最后的优先级,对于实时进程就是按照优先级依次执行;对于普通进程,根据这个优先级来计算权重,然后瓜分CPU时间。
优先级继承:进程fork时,子进程继承父进程的静态优先级,动态优先级并不会提升,确保实时互斥量引起的优先级提高不会传入到子进程.
调度策略
完全公平调度器:
系统对待所有进程都是完全公平的,当然这个公平是假的,只是看起来公平。目的就是消除不公平,挑选等待时间最长的进程来运行。这样消除不公平之后,大家看起来是一样。
虚拟时钟,流速慢于实际的时钟,依赖于当前等待调度器挑选的进程的数目
调度器处理进程的状态:
1.刚fork后,就会调用wake_up_new_task唤醒新进程,将调度体加入到就绪队列中
2.从就绪队列中删除:
到可中断,不可中断状态:主动睡眠并且调用schedule()来让给其他CPU,从就绪队列中移除
3.从睡眠状态回到就绪队列
睡眠的时候将自己挂在workqueue上,等待有人来唤醒自己,然后在唤醒的时候就会重新有机会添加到
prio_to_weight数组是根据根据nice值定义的,一般的概念是进程每降低一个nice值,则多获得10%的CPU时间,每升高一个nice值,则放弃10%的CPU时间。为执行该策略,内核通过这个数组将优先级转换为权重值。而prio_to_w,ult数组和prio_to_weight数组中相同索引的值的关系是prio_to_wult[i]=2^32 / prio_to_weight[i],之所以引入这个数组是避免在计算虚拟运行时间时执行除法。内核中使用delta_exec * (NICE_0_LOAD / weight)的公式来将实际时钟时间(delta_exec)转换为虚拟运行时间,通过prio_to_wmult就可以将这个公式转换为(delta_exec * NICE_0_LOAD) * inv_weight >> 32,将除法很巧妙地转换为乘法和移位操作。
理想时间片的计算:
1.确定物理时间周期:当前有n个进程,如果小于阈值(sched_latency/sched_min_granularity),物理时间周期为sched_latency;如果进程非常多的话,为了防止进程的频繁切换,设置了一个最小的运行时间:sched_min_granularity,此时一个物理时间周期为:n x sched_min_granularity;
2.计算自己的理想运行周期:s = p*P[w/rw]:物理时间 * 自身权重 / 总权重
3.计算虚拟理想运行周期:物理周期 * NICE_0_LOAD / 自己权重
ENQUEUE和DEQUEUE对rq的影响:
每次有新的进程加入到rq上时,重新计算整个rq的weight,加入到rq中,然后重新计算所有的时间片。特别是如果新进程优先级比当前进程优先级更高,那么就会发生抢占,设置抢占标志。
进程从rq中移除时,问题相对没有那么大。
rt熔断
在霸占CPU方面是有绝对的优先级的:硬中断>软中断>实时任务>普通任务,用户程序可以通过 taskset:cpu亲和性 chrt:任务的实时性 在有实时任务的时候,只要它不主动让出来,普通任务就根本不会运行。而实时任务也是有bug的,有时候就一直 霸占着cpu,普通任务就完全没有办法运行,优先级的调整已经解决不了这个问题了,这个是质的差距,已经 不是钱多钱少的问题了,此时登录都是问题。为了避免实时任务把所有的cpu时间都霸占了,出现了熔断机制, 在一段时间内实时任务霸占该CPU的时间不能超过熔断值,超过了立马强行停掉。
$ cat /proc/sys/kernel/sched_rt_period_us
1000000
$ cat /proc/sys/kernel/sched_rt_runtime_us
950000
抢占
进程切换分为两种:自愿切换和强制切换。
自愿切换的标准就是:从rq中移除,然后进入INT,UNINT状态,等待IO,资源等情况。
强制切换是自身迫不得已被踢出CPU,自身仍然在rq上,等待机会重新占用CPU。
自愿切换就是进入INT/UNINI状态,UNINTERRUPTIBLE状态只能是在内核中主动进入。INTERRUPTIBLE
可以接收信号,用户空间时可以通过signal来发送信号来唤醒INTERRUPTIBLE的进程的
信号完全就是软件的概念,不是硬件上的概念,可以看成软件中断,你可以自己注册信号处理,也可以使用系统
默认的信号处理方法,当然有些信号用户空间没有权限处理。
强制切换就是自身被强制切下来了,一个是自身时间片用完了,这个就是发生在周期性的tick中断中,检查
自身时间片是否大于理想运行时间。另外一种是有更高优先级的进程出现了,需要优先运行高优先级进程,
再细分为几种:进程唤醒,进程创建唤醒,进程优先级动态提升。
切换过程:设置当前进程TIF_NEED_RESCHED标志,执行进程切换,中间的过程不是原子性的,所以分开来说。
何时会设置TIF_NEED_RESCHED:就是切换的时候设置:自愿切换和强制切换。
执行切换:检查TIF_NEED_RESCHED标志,如果设置的话就执行抢占。
用户抢占和内核抢占,其实感觉用户空间抢占说法比较奇怪,用户的代码肯定没有权限来抢占其他进程,所有的
还是系统代码来做,不知道为什么叫用户空间抢占。两种情况:系统调用返回和中断返回用户空间(用户空间进入内核空间只有这两种途径)
内核抢占:内核有些位置是禁止抢占的,从禁止抢占的位置离开的时候就会检查TIF_NEED_RESCHED标志。
schedule
任务被调度运行的时间受下面的影响:硬中断,软中断,实时任务,是否启用cgroup,任务的亲和性,nice值
硬中断最优先获得cpu时间,然后才是软中断,之后是实时任务,最后才是普通任务,这4个阶级不可逾越,只有
在同等阶级之间才能谈竞争,不同阶级之间是没有竞争的,只有碾压。
普通任务的竞争通常会受几方面影响:cgroup,如果设置了cpu使用权重那就需要在group间先进行时间片竞争,
之后才是group内竞争;如果使用了配额,那group内所有任务就限定了cpu时间片,仍然是先在group间竞争,
之后group内开始竞争,不过设置了上限,当cpu比较空闲的时候cpu宁愿闲着也不能给你用.
任务的亲和性:当任务限定在某些cpu上的时候,任务就和cpu上其他任务进行时间片竞争。可能负载均衡能够挪走其他任务,如果挪不走的话就相互PK吧。
相应速度受内核的抢占特性影响:完全抢占、只有用户抢占、完全不抢占
负载均衡
负载均衡泛指所有占用cpu时间的,分为硬中断,软中断,rt任务,普通任务
在多核系统中,即我们通常说的SMP系统中,每个核上的任务的调度都是按照单核调度策略来进行的,但是有个
问题,在运行过程中,一个cpu任务很多,另外几个cpu比较闲,不符合兄弟道义啊,应该有难同当啊,所以需要
有个机制来在多核间进行任务的调度平衡,这就是通常说的负载均衡。负载均衡通常有两种方式:pull和push,
自己很闲的时候就问一下其他cpu来pull一些任务过来,另外就是很忙的cpu发现自己很忙,有个cpu很闲,所以可以push一些任务过去。
而rt任务的负载均衡为:N个优先级最高的RT分布到N个核,任务小于N时那就随机的选择cpu来运行,任务大于N时选择前N个优先级最高的
硬件中断的负载均衡,专门有一个进程来通过/proc/irq/x/smp_affinity设置亲和性来均衡,中断控制器
自身并不关心中断均衡问题,而是留出接口来供用户程序来设置均衡策略
软中断的负载均衡,通常出现问题的网络接收软中断,网卡是单队列的时候,通常是只能有一个CPU在处理,
而RPS使用软件的方法将网络数据发送到多核上处理,通过/sys/class/net/ethx/queues/rx-x/rps_cpus
来设置cpu亲和性。
各种负载的均衡可以通过top一下来看,硬件中断看top的hi字段和/proc/interrupts,软中断看
top的si字段和/proc/softirqs,实时进程和普通进程都是进程,通过/proc/x/sched中policy
%Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
负载均衡时机
在每次tick的时候触发负载均衡,然后就开始检查是否需要负载均衡
idle时检查是否进行负载均衡
fork/exec时检查负载均衡
bigLITTLE
arm调查发现,有些任务对于CPU的需求不是很高,CPU性能高低对他们来说没有影响,因此可以放在比较弱的 CPU上也能取得执行相似的效果,而这类CPU的主频较低,电压也较低,功耗低,这就是ARM公司的bigLITTLE设计
负载计算
负载均衡策略
调度域,调度组
亲缘性绑定
cgroup
cgroup使用namespace的功能来进行资源的控制,按照大的分类,有cpu,内存,io,net.其中对于cpu的限制 为配额使用和限制cpu数目,可以用来兜售服务;另外可以进行按照比例划分使用,可以用来确保公平还可以用来划分任务的优先级;
# mount -t cgroup none cgroup/
对于cgroup的使用
linux的实时性
Linux不是一个硬实时系统而是一个软实时系统,硬实时要求的是在期望时间程序立即被执行,要求的是立刻
响应,而linux本身的设计是一个软实时系统,只能尽力保证,但不是一定。
根本原因是在某些环境下不能被抢占,在Linux中总共有两种上下文:中断上下文和进程上下文,中断上下文
又分为硬中断和软中断,进程由分为实时进程和普通进程,在进程上下文中又有一种特殊的时刻:获得锁,当
获得锁的时候可能不响应中断,其他情况下的运行优先级:硬中断>软中断>实时进程>普通进程.
成为实时性任务的方法通常是将自己的调度策略sched_setscheduler设置为实时调度策略:FIFO,RR,BATCH等
但是就算是你成为实时任务,前面还有两头拦路虎,一个是中断,一个是锁,无法保证自己成为最牛逼的任务。
所以rt-linux的做法就是搬开两头拦路虎,将中断线程化,就是在一个优先级最高的实时进程中处理中断。
spinlock锁会禁止中断和抢占可以变成可以睡眠的信号量,之后从理论上系统变成了随处可抢占的系统,能够保证10(不明白)ms内的响应速度。
但是linux内存管理方式对于实时策略的任务会有影响,lazy分配物理内存页方式会有缺页中断的延迟,所以任务要想成为实时任务,还要处理内存管理的坑
对于系统是否需要硬实时性需要分析和测试,业务场景是否需要硬实时,实时精度为多少。 rt-linux的实时精度是有限的,需要对它进行测试,不满足实时精度的话直接上RTOS吧.