网络tuning
NIC:Network interface card,网络接口卡
RPS:Receive Packet Steering,接收数据引导
GRO:Generic Receive Offloading
RFS:Receive Flow Steering,多个数据流中,同一个数据流都流向同一个CPU
网络框图
原文链接
很多事情是在初始化的时候搞的,所以很有必要来看初始化的时候都干了什么
初始化
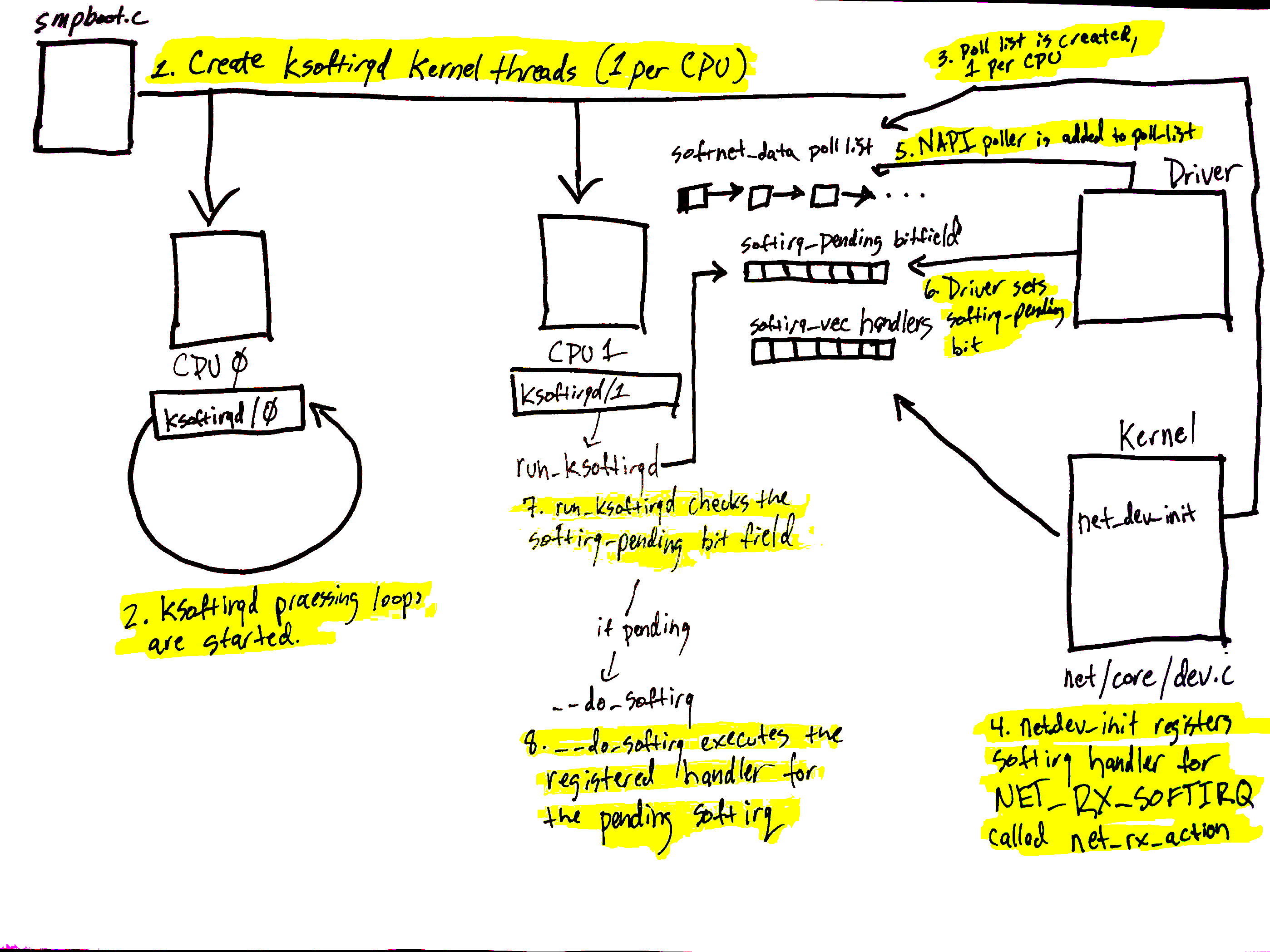
在内核中,设备通过中断的方式来告诉CPU某些事件需要处理,在网络中更是如此,网卡设备通常都是中断CPU通知有新的网络包到了。我们都知道,在Linux系统中中断的优先级是最高的,除了在禁止中断的时候,中断处理可以终止任何的程序上下文切换进入中断上下文,在中断处理中最少也是要禁止本中断线,有时候还会禁止全局中断,为了减少因为中断处理时间比较差而遗漏掉的中断事件通常将中断处理分成上半部和下半部,而下半部通常就是我们说的软中断(另外一方面,软中断只是下半部的一种机制,还有tasklet和workqueue,不过后两种都是基于软中断的).
将中断处理中可以推后处理的部分放在软中断中,总共有32个软中断号静态注册软中断,目前只有12个软中断号被使用,其中最开始的意图就是为了收发网络数据。在内核启动过程中就会注册软中断且在每个cpu上开启了一个ksoftirqd线程,这个线程主要是在软中断事件过多的时候,为了不完全霸占CPU而是将软中断处理集中延迟处理,这个线程的优先级很低的(nice=19),只有当没有其他用户空间进程的时候才会运行该线程.
网卡驱动注册的时候干得一件非常重要的事就是注册中断处理和软中断处理程序.
软中断初始化过程:
通过在kernel/softirq.c中调用spawn_ksoftirqd,然后到kernel/smpboot.c的smpboot_register_percpu_thread,为每一个CPU都创建了一个ksoftirqd线程
.在ksoftirqd执行run_ksoftirqd任务,将会在一个无限循环中一直不停的执行.
为每一个cpu创建一个softnet_data对象,这些对象里面保存了处理网络流量时的重要数据。其中一个就是我们反复看到的poll_list,NAPI将会通过napi_schedule或者其他的NAPI的APIs来添加到poll_list中。
net_dev_init中将会通过open_softirq来注册NET_RX_SOFTIRQ软中断到系统中,而其回调方法就是net_rx_action。
接收数据
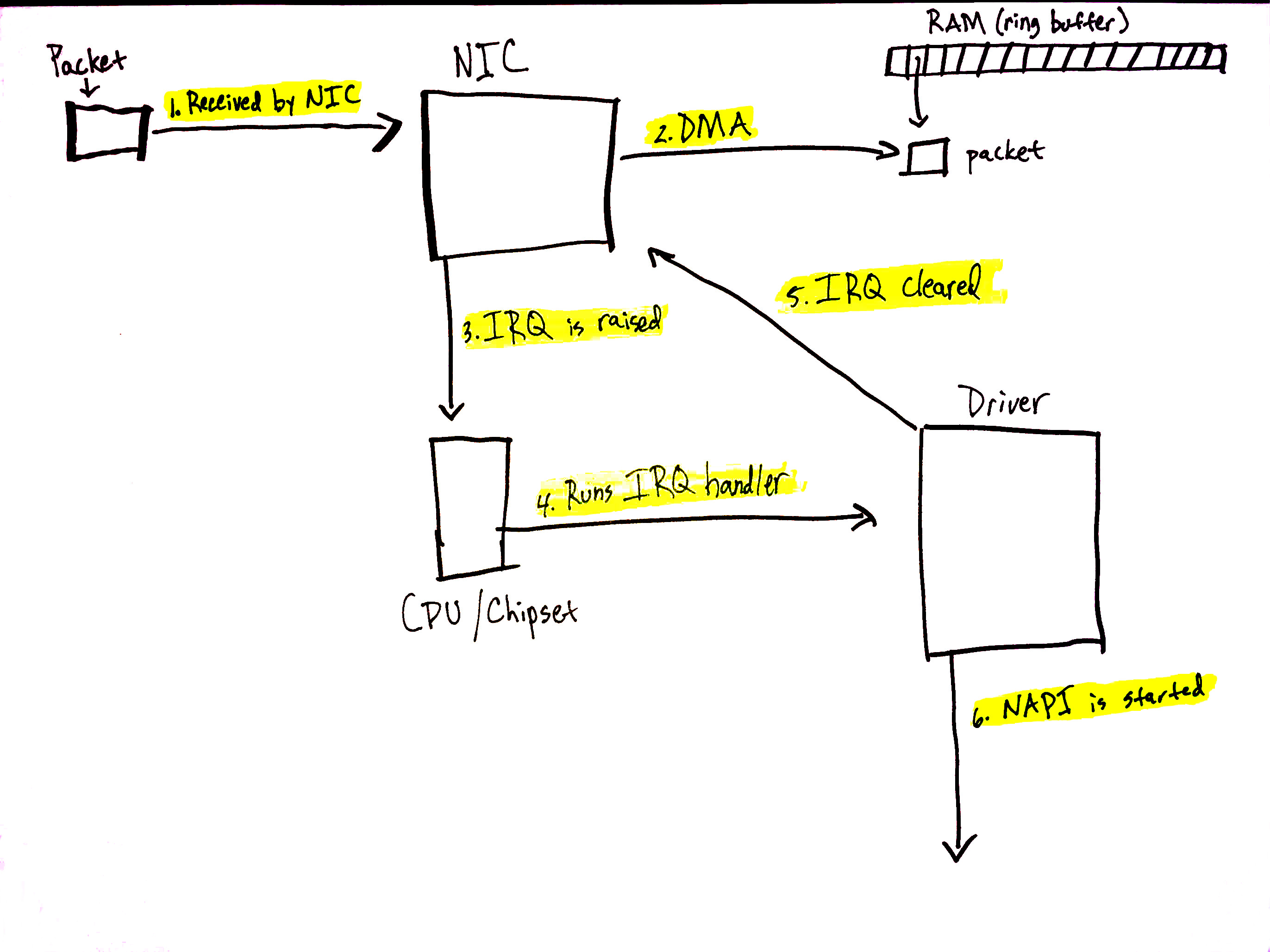
当NIC从网络上接收到数据时,将会利用DMA将数据搬移到RAM中。在igb网卡驱动中,申请了一块RAM,使用ring buffer环形队列机制来管理这块RAM,就是为了存储接收到的网络数据包。
目前有一些NIC支持多个队列,就是在接收到网络数据是,可以使用DMA搬移到不同的队列中。一些NIC就可以根据多队列,充分利用多处理器来处理网络数据包。如果你需要了解多队列的NIC,找些sheet看看吧.
上图所展示的只是一个单队列,实际中情况需要看你使用的NIC是否支持多队列特性和一些软件上的设定。
上图中展示的接收数据的部分过程:
1.NIC从网络接收到数据
2.NIC使用DMA引擎来将数据搬移到RAM中
3.NIC通知CPU中断
4.在NIC初始化时注册的中断方法被调用
5.CPU清楚NIC的中断标志位,当接收到新的数据包时可以再次产生中断
6.NAPI注册到软中断中的`poll`方法被用来调用
在初始化时做的工作在中断处理中会调用napi_schedule,设置state的状态位并且将napi_struct添加到softnet_data->poll_list中,后面在软中断处理中会从链表中遍历所有的napi_struct并逐一处理。
开始处理网络数据
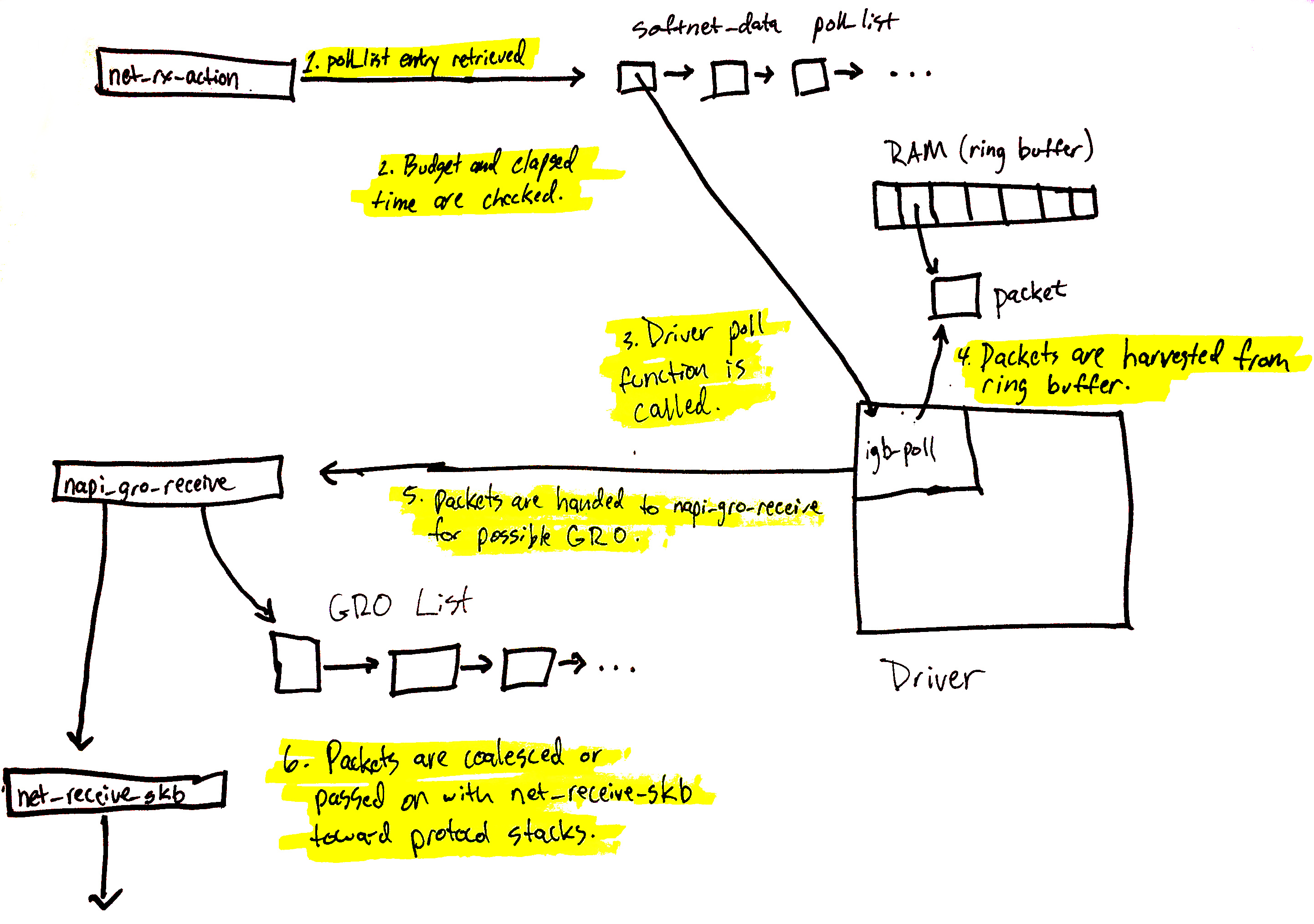
现在开始真正的数据处理,最开始是在软中断中处理,但是为了避免软中断太多,完全不给用户进程机会,所以设置了两个上限:数量和时间.当两个任一条件超出就会退出软中断处理,将剩余的处理延迟到ksoftirqd中。下面我们来看ksoftirqd中调用net_rx_action开始处理在当前CPU上所有的NAPI的poll。
poll通常在两种情况下被添加到cpu的softnet_data:
1.设备驱动调用napi_schedule
2.在启用RPS时发起IPC中断时
下面将会看一下处理poll_list上的napi_struct时会发生什么:
上图可以概括为:
1.net_rx_action开始遍历poll_list的napi_struct对象
2.然后将会检查budget(预计可以处理最大的数据包)和时间,来保证软中断不会消耗完所有的CPU时间
3.注册的poll方法将会被调用,在igb中就是igb_poll
4.驱动的poll方法将会从RAM中的环形队列中获得数据包
5.napi_gro_receive将会继续处理数据包,其中会检查是否启用了GRO特性
6.当通过GRO来处理时,调用关系链在此就结束了;没有通过GRO处理就会直接在net_receive_skb中处理。两种路径最终都会将数据交给上面的协议层进行处理
下面来看一下net_receive_skb中如何使用RPS来将包分发到多核中处理
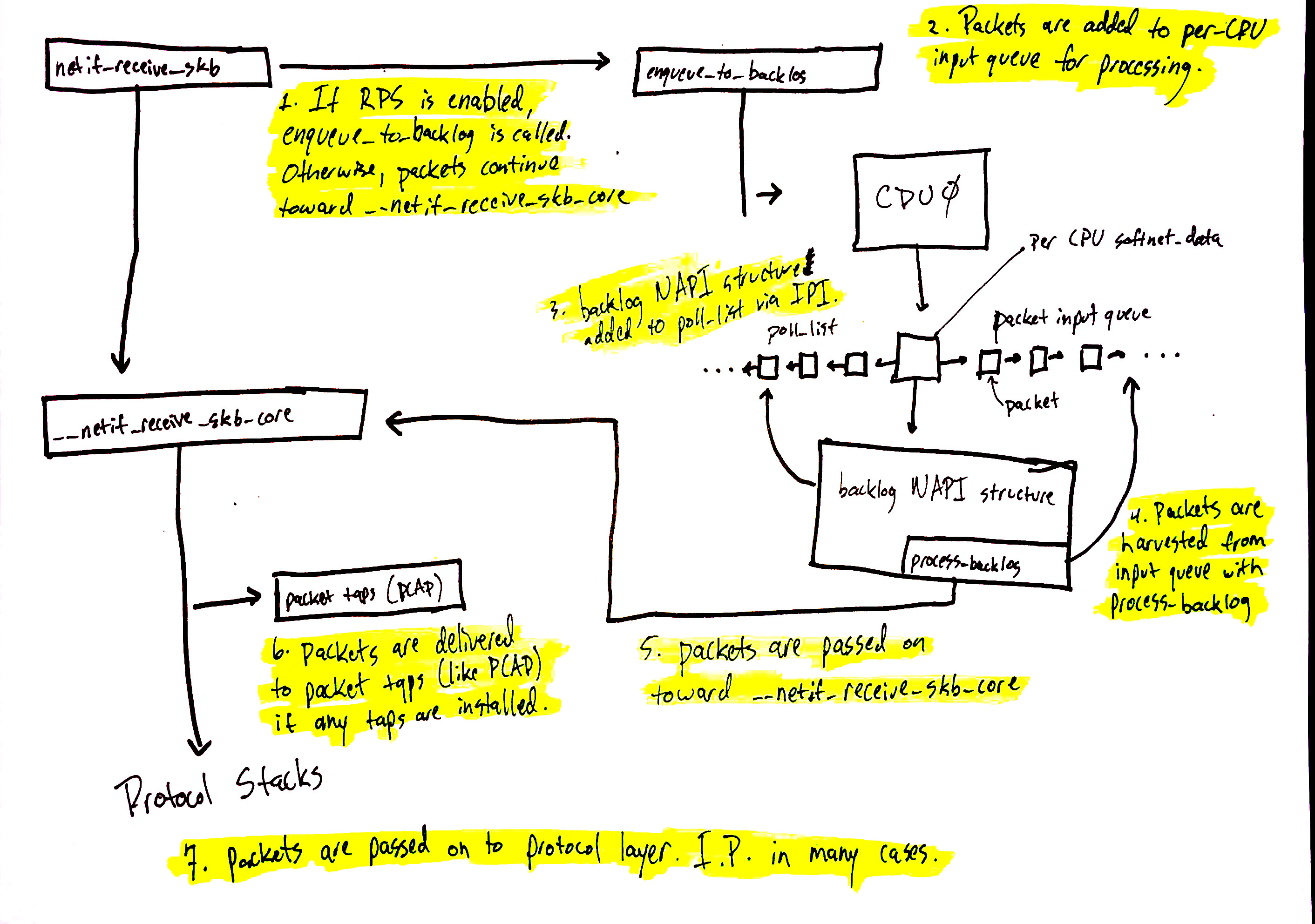
在netif_receive_skb中的处理,根据是否启用RPS可以分成两个执行路径。默认的Linux内核时没有启用RPS,需要具体地使能和配置才能启用这个特性。
在RPS特性没有启用
netif_receive_skb传递数据给__netif_receive_core
__netif_receive_core复制数据给所有注册的tap
__netif_receive_core分发数据给注册的协议层处理入口。在ipv4中就是ip_rcv
当RPS特性启用时:
1.netif_receive_skb调用enqueue_to_backlog
2.包被放到per-CPU的输入队列中等待处理
3.其他CPU的napi_struct对象被加入到CPU的poll_list,发起核间中断IPI来触发其他CPU的ksoftirqd线程
4.当ksoftirqd线程在其他CPU运行的时候,在前面的章节中都是同样的方法来处理,但是这里,poll方法是process_backlog,从当前CPU的输入队列中挪走数据包
6.包经过处理进入到__net_receive_skb_core
__netif_receive_skb_core复制数据给所有注册的tap
__netif_receive_skb_core分发数据给注册的协议层处理入口。在ipv4中就是ip_rcv
协议栈处理和socket接口
下面就是协议栈,netfilter,bpf,和用户socket.代码路径很长,不过逻辑相对简单,相对直白。
对这段路径的高度概括:
包被ip_rcv接口处理,进入到IP协议层中
Netfilter和路由优化环节
数据继续向上到更高层的协议,例如UDP等。
数据被UDP协议层的udp_rcv处理,然后通过udp_queue_rcv_skb和sock_queue_rcv被插入到用户面的sock下的接收buffer中.
在插入到接收队列中时,bpf会对其相应处理
网络调节
网卡相关
NIC驱动都实现了ethtool相关的方法,当然实现的多少和具体的硬件特性,驱动版本相关的,所以针对网卡调节的工具是ethtool
网卡驱动可能有多个接收和发送队列,当有多个队列的时候可以多个DMA操作并行搬移数据,这样处理数据的速度肯定会提升;每个队列的大小也可以调节,可以通过增加队列的长度来容纳更多的网络数据;
网卡还可以将中断打包,传统的是来一个数据包就发送一个中断通知,频发打断CPU,可以设置中断发起的频率,从时间和空间上来设置,接收数据之后n时间如果再没有数据接收到就发起中断,超出多少了个数据包才发出中断。这两种角度的考量在脏页回写的调节上也有体现。时间和数据包设置的比较小时,延迟更小,但是影响CPU的效率
上面是增加网络数据的接收能力和中断触发速度,然后下面就是软中断处理过程。
软中断调节
在软中断处理时,如果过多的软中断占用CPU则会让用户程序完全得不到执行,系统响应就慢。软中断处理中有两种方式来将过多的软中断交给ksoftirqd来处理:
1.时间上是否过长
2.数据数量是否过多
sock的buffer
Cache利用率
硬件中断在CPU A上发起,那么在硬件中断退出时就会尝试软中断处理,即他们是在同一个CPU处理的,cache的利用率更高一些。如果用户空间使用该socket的程序能够也绑定到该CPU上,那么从上到下就完全保持CPU,此时需要设置用户程序的cpu亲缘性和中断的cpu亲缘性
RPS
RPS启用单一NIC rx队列被几个CPU的softirq负载,加速从NIC rx队列中流出的速度,防止单一NIC rx队列
的网络流量瓶颈
/sys/class/net/ethX/queues/rx-N/rps_cpus
RFS
存在多个数据流时,可以根据包的特性计算出来一些hash值表征不同的数据流,将同一数据流发往同一个CPU处理,可以保持CPU cache比较热
工具
iptraf
netstat
monitor
1.网卡驱动的RAM队列缓冲满了造成包丢弃
ethtool -S ethX
/sys/class/net/ethX/statistics
/proc/net/dev
如果减少这种丢包情况,可以更快地排空RAM中环形队列,增大队列数目,队列的大小
排空队列的速度可以调节:
/proc/sys/net/core/netdev_budget和/proc/sys/net/core/dev_weight,在软中断处理中允许处理更多的数据包,但是内核里面超时时间总是2*jiffies,调的再大也没啥用处
启用RPS特性来利用多核处理环形队列
队列数目和队列大小可以使用ethtool来设置网卡驱动的参数,是需要网卡硬件和驱动版本支持的
启用RFS特性更多的利用cache
2.中断触发的速率和亲和性
3.per-CPU上的softnet_data统计
net_rx_action退出的时候会进行一些统计,记录在per-CPU的softnet_data中,可以在/proc中查看统计结果
net/core/net-procfs.c:
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,
0, 0, 0, 0, /* was fastroute */
sd->cpu_collision, sd->received_rps, flow_limit_count);
cat /proc/net/softnet_stat
000060e1 00000000 00000036 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00014cf2 00000000 00000163 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00014ad9 00000000 000000fd 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00021d81 00000000 000002b8 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
每一行的显示对应一个CPU,通过空格分割开,16进制显示
sd->processed:已经处理的网络帧数,不过如果你启用了bonding功能,这个值可能比实际收到的网络帧数要大
sd->dropped:在处理队列中没有空间而将数据包丢弃
sd->time_squeeze:在软中断处理中,处理网络帧数过多或时间超时时会终止net_rx_action,此时会更新该统计
sd->cpu_collision:当传输包时,尝试获得设备锁来发送数据时发生的竞争事件
sd->received_rps:通过IPI中断来唤醒其他CPU帮忙处理队列数据的计数
flow_limit_count:RFS中flow匹配的计数